
TEMA 9
TEMA 9: INTRODUCCIÓN A LA INFERENCIA
ESTADÍSTICA


Se define como el conjunto de procedimientos estadísticos que permiten pasar de lo
particular (la muestra) a lo general (la población).
- Muestra independiente: Está formada por datos independientes, o sea, aquellos obtenidos tras una única observación.
- Muestra apareada o dependiente: Está constituida por datos emparejados. Comparan el mismo grupo de sujetos en dos tiempos diferentes, o bien son grupos muy relacionados entre sí.
Nos encontramos dos formas de interferencia estadística:
- Estimación: Son puntuales o a través de intervalos de confianza
para aproximarnos a valor de un parámetro.
- Estadístico o estimador: Índice que representa una información de la muestra estudiada. Se representa con el alfabeto latino. Produce insesgadez, eficiencia y consistencia.
- Parámetro: Cada uno de los estadísticos que tras inferirse, nos proporcionan información sobre la población. Se representa con el alfabeto griego.
- Estimación puntual: Se considera al valor del estadístico muestral como una aproximación del parámetro poblacional. Manejo de incertidumbre e imprecisión.
- Estimación por intervalos: Se calculan dos valores entre los cuales se encuentra el parámetro poblacional. Son indicadores de la variabilidad de las estimaciones. Cuanto más estrecho sea, mejor.
- Test o contraste de hipótesis: Se comprueba si el valor obtenido es diferente del valor
especificado por H0. También nos ayudan a controlar los errores aleatorios, analizando la coherencia de entre la hipótesis previa y los
datos obtenidos.
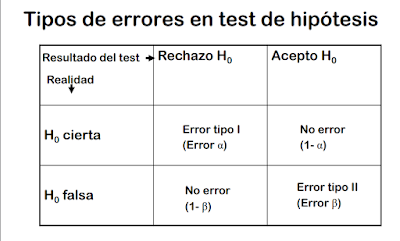
- Con una misma muestra podemos aceptar o rechazar la hipótesis nula, todo depende de un error, al que llamamos α.
- El error α es la probabilidad de equivocarnos al rechazar la hipótesis nula
- El error α más pequeño al que podemos rechazar H0 es el error p.
- Habitualmente rechazamos H0 para un nivel α máximo del 5% (p)
| MÉTODOS NO PARAMÉTRICOS | MÉTODOS PARAMÉTRICOS |
| Mayor potencia estadística | Mayor potencia estadística |
| Variables categóricas | Variables normales o de intervalo |
| Se utilizan para muestras pequeñas | Se utilizan para muestras grandes |
| No se conoce la forma de distribución de datos | Su distribución de datos es normal |
| No hacen muchas suposiciones | Hacen muchas suposiciones |
| Exigen una menor condición de validez | Exigen mayor condición de validez |
| Mayor probabilidad de errores | Menor probabilidad de errores |
| El cálculo es menos complicado de hacer | El cálculo es complicado de hacer |
| Las hipótesis se basan en rangos, mediana y frecuencia de datos | Las hipótesis se basa en datos numéricos |
| Los cálculos no son exactos | Los cálculos son demasiado exactos |
| Considera los valores perdidos para obtener información | No toma en cuenta los valores perdidos para obtener información |
ERROR ESTÁNDAR
Mide el grado de
variabilidad en los valores del estimador.
- Error estándar en una media: 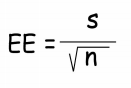
- Error estándar para una proporción (en variables cualitativas): 
P es el porcentaje o proporción a estimar
S es el valor de la media
N es el número de sujetos de la muestra
TEOREMA CENTRAL DEL LÍMITE
Si sigue una distribución normal (los estimadores son la suma de los valores muestrales):
INTERVALOS DE CONFIANZA
Se mide el error aleatorio. Son un par de número con los que podemos asegurar que el valor del
parámetro es mayor o menor que ambos números. Es establecido con la teoría central del límite, por lo tanto, se sigue una distribución normal.
Para construir un intervalo de
confianza del 95% o del 99%
se aplica la fórmula:
– Para nivel de confianza 95% z=1,96
– Para nivel de confianza 99% z=2,58
Z es un valor que depende del nivel de confianza 1-a
con que se quiera dar el intervalo
Los dos números obtenidos indicarán el intervalo de confianza.
Comentarios
Publicar un comentario